Introduction
Word Embedding exist for a few years now, and its known by many names such as distributed representation, Word2Vec, word vectors etc. Surprisingly, I know from speaking to various data scientist, not many people in the data science field know what it is, or how it works. It’s a difficult concept to grasp and it’s new to me too. So I’ve been reading various blogs, doing lots of research, and I have found a few ones that explains the concept really gracefully (short, sweet and easy to understand). Despite that however, I noticed there was a lack of coverage around the applications of it, such as how to use it and apply it on various real life challenges in predictive modelling.
The way I understand a lot of these complex / abstract methodologies is through applications first. Having seen the end results, I understand easier by working backwards. Seeing that it works to begin with, makes it worth the effort to try and understand it. After all, what good is word embedding if it doesn’t add any commercial value right? So for my blog post, I will focus on word embedding applications and how it helps improve your predictive model as a powerful feature.
To make this post short, I will skip explaining the details of how it works. Rather, I will direct you to these blogs post below which I have carefully curated while I was research this topic:
- https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
- https://rare-technologies.com/making-sense-of-word2vec/
- https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
Whilst I won’t explain word embedding in its entirety, I will briefly introduce the word embedding concept through an analogous example…
Analogy of dimension reduction
“Hashtags” is a good analogous example. A hashtag is a keyword or phrase preceded by the hash symbol (#), widely used in social media to categorise our content or post on a sub-topic that is related. For example, I may take this post to twitter and write this:
“Hey guys, I’ve released a new post on word embedding, a machine learning technique, go check it out! #MachineLearning, #AI, #wordembedding, #DataScience, #bloggersRule, #TextMining, #NLP“, #EuJinLokTrending, #MarvelActionHeros
Think of word embedding as some form of algorithm where it tries to find hashtag topics for your data. And in order to do so, it needs to understand the context of your post and determine if there’s enough common topics to justify a hashtag. Using the example above, #EuJinLokTrending is not going to come through because its just going to be one instance of that topic. And so is #MarvelActionHeroes, for the reason being that the post is on the wrong topic.
Finally the word embedding retains just the hashtags topics, stores the words and its relationship to the hashtag topics (eg. words like “machine” has close relationship to topics under Computers, Engineering, or agriculture. Less likely on economics or religion) and discards the original full text. Should there be enough demand, I will consider posting my version of explaining how word embedding work.
The objective and the experiment
So I’m going to need some datasets to get us started. Whilst planning for this post, I was searching everywhere in the wild for a dataset, and then I had a brilliant idea. So I’m going to use 2 datasets from Kaggle:
And I’m going to use the News Aggregator as my primary dataset, with the key objective to build a document classifier to classify the news into the correct categories, by just using the title of the news. The word embedding model will be built on the News Group dataset instead.
To proof how word embedding can improve accuracy, I’m going to run two experiments:
- Building the classifier just using features from the News Aggregator dataset only
- Using the same process as above, but supplement with word embedding features
- Building the classifier with just the word embedding features only
The hypothesis of course, is that the accuracy of the predictive model will be higher with the use of word embedding as features.
Without further ado, lets begin the experiment!
Just give me the code
If you are already familiar with word embedding and just want to dive into the code to see the results, here it is:
- Part 1 – Establishing the benchmark for comparison
- Part 2 – Use Word embeddings as features for modelling
- Part 3 – Visualisation of the word embedding model
Setting the benchmark
For this I’ll be using the News Aggregator dataset. There’s already a kernel that someone has started so I’m going to borrow it, as it acts as an independent benchmark. I will however make 3 key modifications:
- Minimise the count vectoriser to just 300 features (to be explained later)
- Build the vectoriser on just the Training dataset, and the test dataset is fitted on. This is good practice in real world scenarios
- Using n <= 500 as sample size for training
So go to this link here to view the notebook to obtain the accuracy based on the above. And here’s a brief walk through of the process in plain language:
- Read in the news aggregator dataset from csv file
- The dataset has a few columns in it, but we’re only insterested in news title, and its category
- Separate the target / label into its own variable then split the dataset in train and test. 99.9% of the data is going to be test data, so leaving less than 500 records as training
- Create a document term matrix using the training dataset, keeping only the top 300 most frequent words as features
- Then apply the structure (vectoriser) on the test dataset using the same vocabulary structure as in step 4.
- Finally build a Multinomial Naive Bayes model and get the accuracy score
Essentially, by making the 3 modifications above, I’ve managed to achieve the accuracy of ~0.58. The Accuracy of the original kernel obtained over 92%. The big difference there is due to the lower sample size I’ve used. Why did I use such a small sample size? Partly its real world challenges, partly to demonstrate the value of word embedding to a comparable level. I’ll shed more light on this later here so read on! Also keep in mind the main modelling dataset here is the News Aggregator dataset.
Using word embedding
Now, for the next section, I’ll be using word embedding as features. I’ll be using building a word embedding model using the Word2Vec package in Gensim, on a completely different dataset, the News Group dataset. Yes you heard it right. Instead of building a word embedding model on the same training dataset, I’m going to be building it on a different one. Why did I do this? See the section below on ‘So what’s the big deal?’
Now go ahead and open up this notebook here to step through the process. And for the process in plain language:
- Read the News corpus dataset. Its a pretty complex loop as its trying to read text files that is distributed across various folders. I nipped this code from the Keras website.
- Now that we’ve got all the text data into one single object, we then break them into sentences which is the format needed by word embedding (we’re using Gensim’s word2vec)
- And now we initialise the parameters for our word emebedding model:
- 300 features / dimensions, which is default. Could go larger
- Minimum word count of 40 which will eliminate really rare words from the model
- 4 workers to allow faster build
- 10 word context, wherein for each word we consider 5 words before it, and 5 after it
- Set sampling rate to default of 0.0001. Safe choice as this can be quite tricky to select…
- Using CBOW, which is default on word2vec
- Once complete, run a few test to see if a random word chosen from 2 or 3 topics does make sense. I’ve chosen ‘economy’ (try ‘money’) and words like ‘growth’, ‘investment’, ‘monopoly’ all come up which makes sense since they were about economics and business. If words that were in no way related came up like ‘baseball’, you know something went wrong
- I’m happy with the word embedding model. So put that word2vec model aside now, lets now work through our main working dataset, the News Aggregator. Despite the similar naming, this dataset is different from News Group.
- Read in again the News Aggregator dataset. Then for each text row in the dataset:
- break them into a string of words and remove the stopwords
- For each word in the text, do a “v-lookup” to the word embedding model. And if that word exist, retrieve the 300 word dimension from the model
- Once all the words have been worked through, we aggregate them by taking the average (ie. We squash the n X 300 dimension matrix to just a 1 x 300 dimension matrix, by taking the average)
- Once that is done, we replace any Nulls with 0
- Normalise the data to ensure the values are all in a range that the model likes it
- Now that the features from the word embedding is fully prepared, we need to obtain the original features from part 1 so we can start comparing. So go through again the count vectoriser process
- Separate the target / label into its own variable then split the dataset in train and test. And again, 99.9% of the data is going to be test data
- Combined both feature sets together and throw it into the Multinomial Naive Bayes model
- Checking the accuracy results, we see an improvement from 58% to 61%, a small improvement
- Now we will just use the word embedding features only and see how that alone performs. The accuracy is 55% which is similar to the word count vectors
So what’s the big deal?
You might have guessed by now that the reason why I only took the top 300 word count vector features for the benchmark, is just so I can compare with the features from the word embedding model that is also 300 dimensions.
Right now you might be wondering, word embedding gives only a small boost, its hardly worth the effort. After all, a simple word count vectors with just top 300 words, with about 10 lines of code, and gets you ~58% accuracy as opposed to the word embedding which only gives you ~55%, with a highly complex and lengthy code. Yes that is true, but consider this:
- The word embedding model is built on the News Group dataset, NOT the training dataset (accuracy would be better if I built it on the News Aggregator data)
- The word embedding model I’ve presented here is not optimal (see Quiz section)
- There is no limit on how many word embedding features I can produce (ie. I can build it on other dataset like Wikipedia, Google news, Amazon reviews etc)
- I don’t need any labels for the dataset when building a word embedding model
So the answer to why I took n <= 500 for the training dataset, that’s because in real life, especially in NLP, it’s very common to get only a small size of labelled dataset. In the workplace, you’ll be dealing with a problem that is very context dependent, so you’ll need to curate your own dataset by hand labeling it first hand. Further more, its hard to find good quality text dataset (minimal noise). Those 2 criteria must be met if you are going to build features that provides good predictive power, which translates to higher accuracy.
The other reason is also because I wanted to show case that word embedding is not affected by the size of your training dataset. In fact, I don’t even need the training dataset. I could just literally just work with the full test dataset.
There are hundreds of great quality dataset in the wild. So in essence, you could continue to include other word vectors trained on different datasets. Heck if you wanted, you could scrape you own dataset for your specific purposes too. And if you don’t want to train you own word embedding model, you can download pre-trained ones instead. Gensim for instance has one.
Visualising word embedding
In this section I present the visualisation of the word embedding model results, fitted on the News group dataset (Not the News Aggregator dataset). The method I’ve used in called T-SNE
T-SNE is a great way to visualise high dimensional data. We can squash it into 2 dimension whilst trying to keep as much information. And because its in 2 dimension, we can plot them as a scatter. Other methods have tried to do this but T-SNE so far is the best implementation
So here’s the full plot:
Here’s how we will use this to validate our word embedding model. Lets zoom into a specific part of the graph, in this case top right (y-axis between 4 and 5, x-axis between 4 and 5):
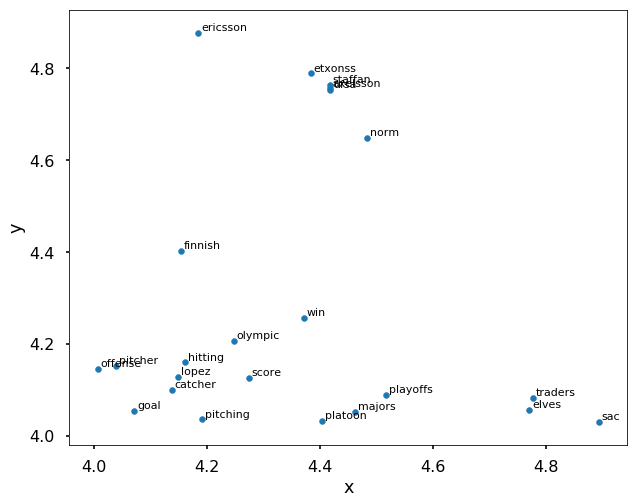
So the top right part of the map shows us words that seem to point to sports concepts. Words like ‘pitching’, ‘score’, ‘olympic’, ‘win’, ‘playoffs’ just to name a few, are all words to do with sports. Now lets look at a different part of the map that is bottom left (y-axis between -2 and -1, x-axis between -5 and -4):

So the bottom left part of the map shows us words that seem to point to computer concepts. Words like ‘username’, ‘shell’, ‘etl’, ‘xdm’, ‘invoke’ just to name a few, are all words to do with computers or IT.
Further enhancement suggestions
Lots more improvements can be made to what I’ve done here as the parameters that I’ve used is really under optimised. And I’ve only covered just one application of word embedding only, in particular CBOW (continuous bag-of-words). Here are the other types of applications:
- Skip-gram approach
- Glove Vectors (word co-occurrence via matrix factorization)
- Fasttext (similar to word2Vec but is at ngram level)
And you can also try other different datasets to build the word embedding models on, such as on the training dataset itself?
Personally in practice, I use Glove for simplicity and practicality, and I will build it on a much much larger dataset like Wikipedia on Google News, or even both! And I’d be using the word embedding differently as well (see Quiz section below), which gives way bigger improvement in accuracy. If this was a Kaggle Competition, this is the path I would have taken (and have taken before).
Quiz
There is a part of the process where a large component of information was discarded after performing some transformation. And because of that, a huge potential for accuracy gain is lost. Can you pick it out?
As a hint, the answer will be covered in a future post. (Think what is the most common method word embedding is used as part of a model these days?)
So to conclude this episode
So I hope this post provides more clarity around the application and value of using word embedding. The next post is still up in the air, and I generally look to the audience as to what they want to see, so drop a comment below if you have a request.
I do feel like investigating deep learning would be fun, but at the same time I think it’s too fast too soon and I should cover some basic grounds first. Here’s a list of topics I have in mind:
- Word embedding part 2 – GloVe and FastText (NEW!)
- DIKW pyramid – a data scientist framework for conversation (NEW!)
- Markov Chains (NEW!)
- Hashing trick
- Information Retrieval paradigms (Vector space vs fuzzy search)
- Practical applications of Network theory to text
- How to make a Spelling corrector (NEW!)
- Collaborative filtering (gateway to Deep Learning)
- Deep Learning archetypes for text (RNN and LSTM)
- Enter a Kaggle Competition (NEW!)
Happy New Year 2018!

Thanks. Very insightful article…I, however, cannot access the code on github.
Hi Vusi. I just tried and it works. You should be able to. Note that they are iPython Notebooks…
Here’s the link again: https://github.com/ejlok1/blogpost.io/tree/master/Episode%203
Ah! I got it to work thanks a lot for this…